LawyerEdge Website Underperforming? A Cautionary Tale of Duplicate Content
 |
September 19, 2013
|
September 19, 2013
Having trouble figuring out why your website isn’t getting more traffic? Its possible the content on your site has simply been cut and pasted from another site – rending your SEO impotent.
Law Firm Website Almost Invisible
Initially, I couldn’t figure out why the law firm’s site was performing so badly – the technology was fine, the content seemed fairly well written and there was a reasonable link profile. Despite this, the site was averaging less than 2 visitors a day from unbranded natural search – and very few of those visitors were landing on the practice area pages. Digging deeper, I found that the actual content on the practice area pages was cut and pasted across other LawyerEdge clients.
In the example below – we can see that Google has identified 58 other pages with the exact same content as this law firm’s page for pedestrian knock down accidents.
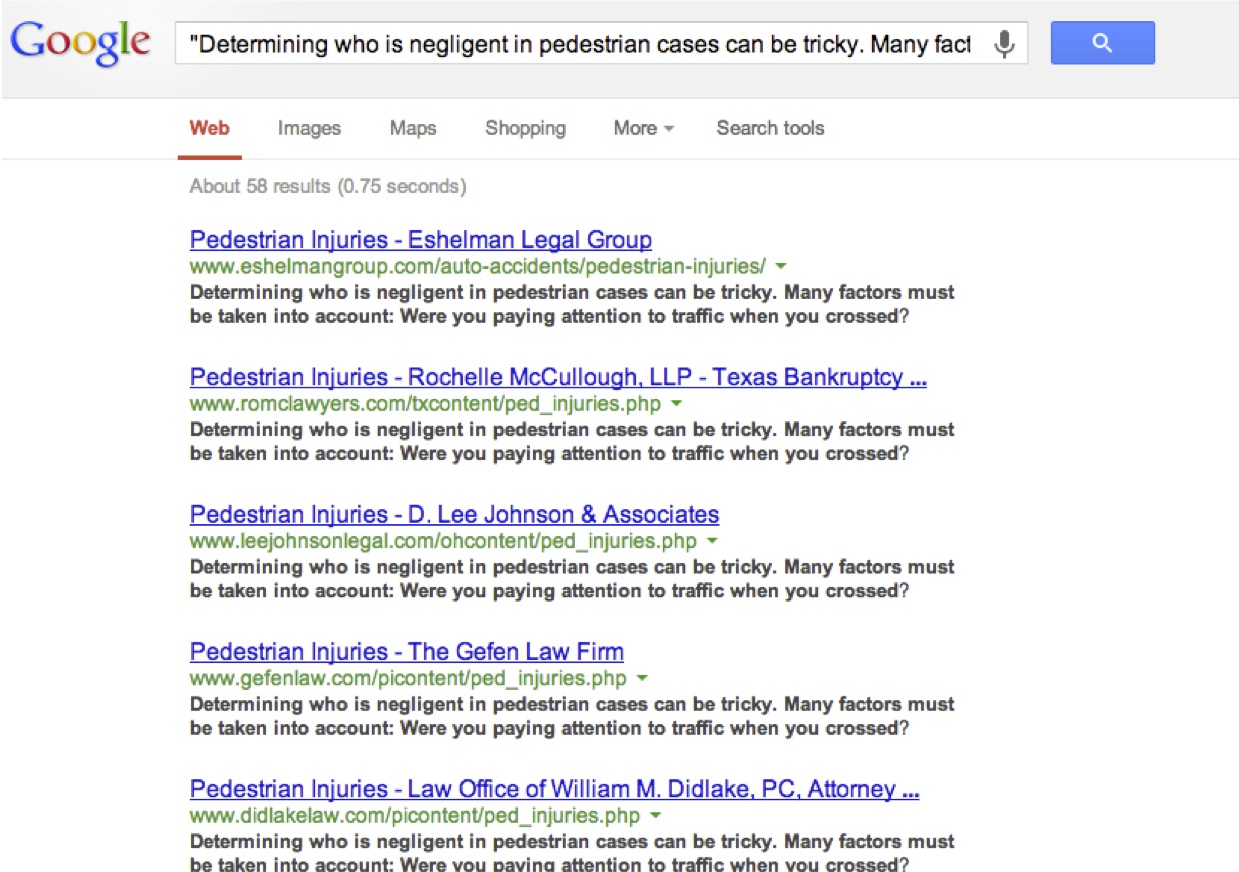
When I looked across the website’s landing pages, I found that almost all of them had content that was duplicated across the web. In the graph below, the vertical axis shows the number of pages found on the web containing the exact same content as the law firm’s topic pages.
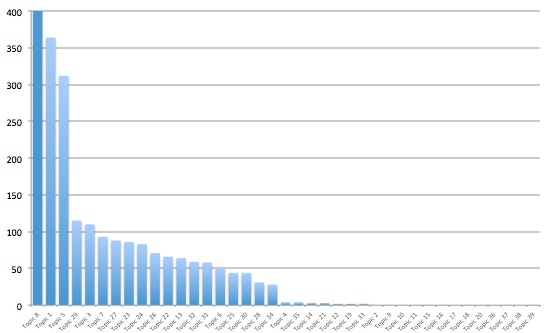
Of the 40 pages I reviewed, just 13 had unique content.
Understanding Duplicate Content
Search engines hate duplicate content because it can generate a really bad user experience. Here’s why: Using the above example, imagine I do a Google search for “determining who is negligent in Pedestrian cases”. The first result I click to doesn’t give me what I’m looking for, so I click back to the search engine and try the second result . . . . which leads me to the exact same content on another site. Now I’m annoyed and instead of clicking back, I load up Bing to try to find something different.
The search engines minimize this poor user experience by identifying duplicate content across different pages and trying to identify the original version of the content (search geeks refer to this as the canonical). Google and bing hide the other pages away from searchers in what is called “supplemental results” – which is of course, where I eventually found the law firm’s pages. Supplemental results are shown here:

This is compounded when a large portion of a site’s content looks to be simply copied and pasted from other sites across the web. Search engines reasonably deduce that the overall site is of pretty low quality wrt to unique, interesting content. Google’s algorithm updated to try to identify (and weed out) these sites with the Panda update. From the Google blog:
“This update is designed to reduce rankings for low-quality sites—sites which are low-value add for users, copy content from other websites or sites that are just not very useful.”
Note that Panda is a site-wide penalty – which means that duplicate content on many pages will impact performance of the entire site – even those deliciously well written unique and insightful pages. The bar graph above, which shows the majority of the law firm’s pages having duplicate content indicates they have most likely been hit by the Panda update.
In the pedestrian knockdown practice area example, all of the firms listed below are competing directly with each other with the exact same content:
- Rochelle McCullough, LLP
- Inkelaar Law
- Eshelman Legal Group
- Joshua D. Earwood
- Saladino Oakes & Schaaf
- Levenbaum Trachtenberg
- Ellis, Ged & Bodden
- Law Office of Bruce D. Schupp
- Allen, Allen, Allen & Allen
- Law Office of Kenneth G. Miller
- The Law Firm of Kevin A. Moore, P.A.
- Buchanan & Buchanan
- S. Perry Penland, JR.
- Ardoin Law Firm
- McWard Law Office
- LeBell Dobroski Morgan Meylink LLP
- Cox & Associates, P.A.
- The Gefen Law Firm
- Echemendia Law Firm PA
- McKinney Braswell Butler LLC
- Law Office of Charney & Roberts
- Johnson & Associates
- Pistotnik Law Offices
- Bledsoe Law Office
- Law Offices of George A. Malliaros
- Roberts, Miceli & Boileau, LLP
- William E. Hymes
- Law Office of Donald P. Edwards
- Ferderigos & Lambe Attorneys at Law
- The Law Offices of Fuentes & Berrio, L.L.P.
- Robert B. French, Jr., P.C.
- The Law Offices of Peck and Peck
- Cherry Law Firm, P.C.
- Dexter & Kilcoyne
- Philip R. Cockerille
- Brotman Nusbaum Fox
- Stephen J. Knox Attorney at Law
- Littman & Babiarz
- The Law Offices of Weinstein & Scharf, P.A.
- Friedman & Friedman
- The Law Firm of Robert S. Windholz
- Fahrendorf, Viloria, Oliphant & Oster L.L.P.
- Conway Law Firm, P.L.L.C.
- Head Thomas Webb & Willis
- Charles B. Roberts & Associates, P.C.
- Pistotnik Law Offices
- Nordloh Law Office, PLLC
- The Law Offices of Rosenberg, Kirby, Cahill & Stankowitz
- Kerner & Kerner
- McAdory Borg Law Firm P.C.
- For a funny one – check out this: The Law Offices of This is Arizona – a template, presumably available for purchase with ghost Attorneys John and Joan Smith.
(To be fair, not all of these firms are LawyerEdge clients – there is a smattering of different agencies. This does highlight the extent to which content gets cut and pasted around the web by website developers.)
How to Tell if You Have Duplicate Content Issues
The most obvious sign of duplicate content, of course is zero to low inbound search traffic to specific pages. You can diagnose this in Google Analtyics using the “Landing Pages” tab under content (make sure you filter for ONLY “organic search traffic”).
Another more accurate approach is to take a unique looking, sentence from your page and doing a search for it with quotations around the phrase:
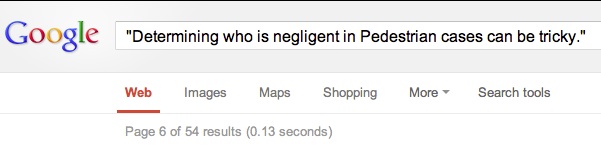
If your search returns a ton of results . . . its time to start writing.
This is insane.
Nice finds Conrad.
What’s your first recommendation to a client like this? Noindex pages until unique content can be developed?
How do you protect your own clients from stolen content? I’ve personally used services like plagspotter in the past with various degrees of success.
I’d love to see a future follow-up post that shows the rebound once dup content is replaced w/ unique. Specifically, how much time it takes for those penalized pages to see traffic.
I’ll stay tuned.
Chris – great idea on the followup!
As far as content getting stolen – if you have a reasonably robust link profile, the search engines are almost certainly going to ID your content first – in which they will usually (but not always) ID that as the canonical version.
In terms of no-indexing – I’d focus instead on just rewriting this quickly and well, unless the problem is extremely widespread and hits a large volume of pages.
Thank you for an explanation which makes complex concepts easy to grasp. It explains a lot about why some firm sites do well despite horribly self-written content.