Problem
Google Search Console is a user-friendly tool that monitors various aspects of a site. This includes working/broken pages, security concerns, and overall performance.
Beginning on July 31, 2020, Mockingbird Marketing was flagged with a “Valid with warning” error in Google Search Console. In this particular case, the error type was “Indexed, though blocked by robots.txt,” meaning that the page can be found in Google searches, but is not intended to be found. This was due to the robots.txt file, a rulebook that search engines read and obey, taking into account which pages to ignore and not read at all. Pictured below is a typical robots.txt file.
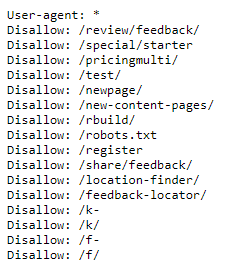
In a normal scenario, this error would be resolved by simply requesting Google bots read the robots.txt file again. Since Google has a finite number of resources, any changes that are made to the robots.txt file may not detect them immediately, thus resulting in errors like this. Therefore, it is necessary to request a Google bot read so that any recent changes are reflected in Google searches. However, upon digging into this problem further, that fix might not address the entire situation.
The affected page was a review page hosted by a third-party company that Mockingbird hired on behalf of our clients. This is definitely a page we would not want indexed. Why? When a review page is accessible through Google searches, there is a possibility that an individual will access the page and leave untruthful reviews, ultimately damaging the reputability of a law firm.
Theory
According to the current robots.txt file, the review page should already be ignored by Google bots. In addition, the third-party company that hosts other Mockingbird clients has not had any problems until now.
Another concern with the robots.txt file is that it also tells Google bots to ignore the robots.txt file itself (Disallow: /robots.txt). In other words, imagine a rule book listing all kinds of rules, but the last rule reading “Do not follow any of the rules listed above.” It is also important to note the position of the “Do not follow…” rule, as it is listed above the original rule in question. This could indicate that Google bots are reading the “Do not follow…” rule first and deciding to ignore all other rules below it.
Results
After a conversation with our contacts from the third-party company, it is clear that it is not their fault nor Mockingbird’s. The problem lies within Google bots not respecting their own rules, as seen with the robots.txt file. The third-party company confirmed my suspicions and suggested that I validate the fix through Google Search Console. This entails requesting Google bots crawl the page once more, read the robots.txt file, and remove the indexability from the review page in question.
Conclusion
After proceeding with the request on August 24, 2020, the URL is still pending and two additional review pages appeared in Google Search Console. If the validation fails, it is probable that the robotx.txt file is being ignored holistically due to the “Do not follow… ” rule. This requires further investigation and may call for another case study.